Cypher
Drop the PDF. Get the table. Walk away.
For three decades, the same scene has played out in airline back offices and lease return rooms across the world, from Shannon to Timbuktu: an analyst opens a 50-page maintenance PDF, triple-screens a spreadsheet, opens a third spreadsheet, and starts typing. Every part number, every serial, every cycle count — by hand. One typo away from a costly mistake. One missed row away from an audit finding.
There has to be a better way.
There is. It just runs in your browser.
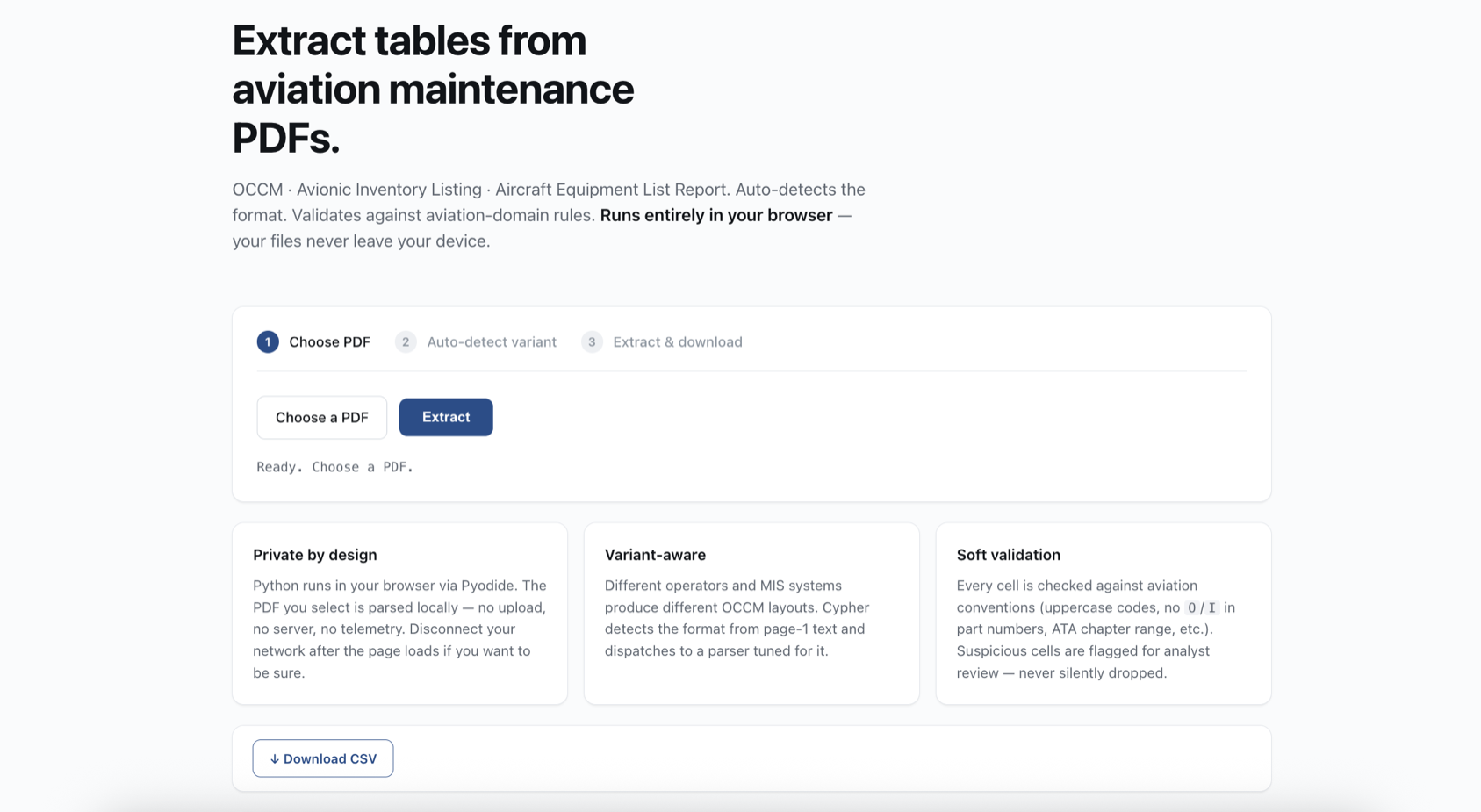
From PDF to validated CSV in three clicks.
What it does, in one breath
Cypher reads aviation maintenance documents — OCCMs, Hard-Time lists, Life-Limited-Part records, Avionic Inventories, Aircraft Equipment List Reports — and produces clean, structured, validated data ready for Excel, your MIS, or your records system. It runs entirely in your browser. Your PDFs never leave your laptop. Nothing is uploaded anywhere. Ever.
That is not marketing language. It is an architectural fact, verifiable in 30 seconds with the browser's network panel.
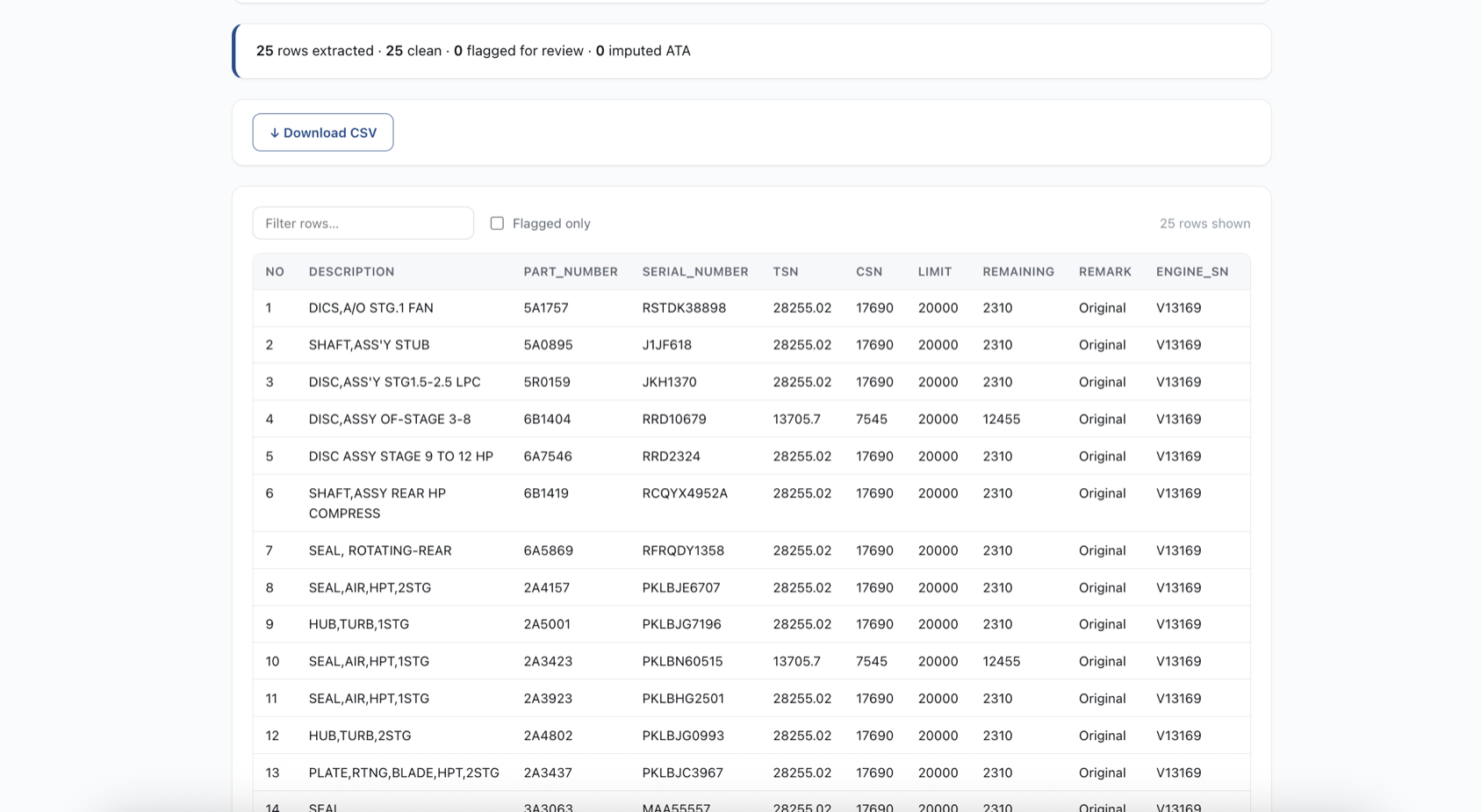
A real Life-Limited-Parts list, parsed in under a second. 25 rows, 25 clean, zero flagged. Engine serial number propagated to every row from the document header so the data is one GROUP BY away from a fleet-wide LLP burn-down chart. Try doing that with a screenshot of a PDF and a hand-typed spreadsheet.
Why it's different
Variant-aware, by construction
Operators don't agree on document formats. China Eastern's OCCM doesn't look like Vietnam Airlines'. Aeroflot ships a scanned PDF with no text layer. AMOS-driven equipment lists from Swiss-AS are line-anchored. Off the shelf standard "PDF table extractors" treat all documents as one shape — and break the moment they don't.
Cypher does not. Every operator gets its own sealed variant module — a single Python file that pins the column schema, the validation rules, and the parser logic. When a new VNA document arrives, it is fingerprinted from the first three pages and routed to exactly the same parser that handled the last 50 VNA documents. Same input shape → same output shape. Every. Single. Time.
Soft validation, aviation-domain-aware
Cypher knows what part numbers contain what string of letters, and which ones don't.
Every cell is checked. Every suspicious cell is flagged for review. Nothing is dropped. The analyst sees what the machine wasn't sure about and decides.
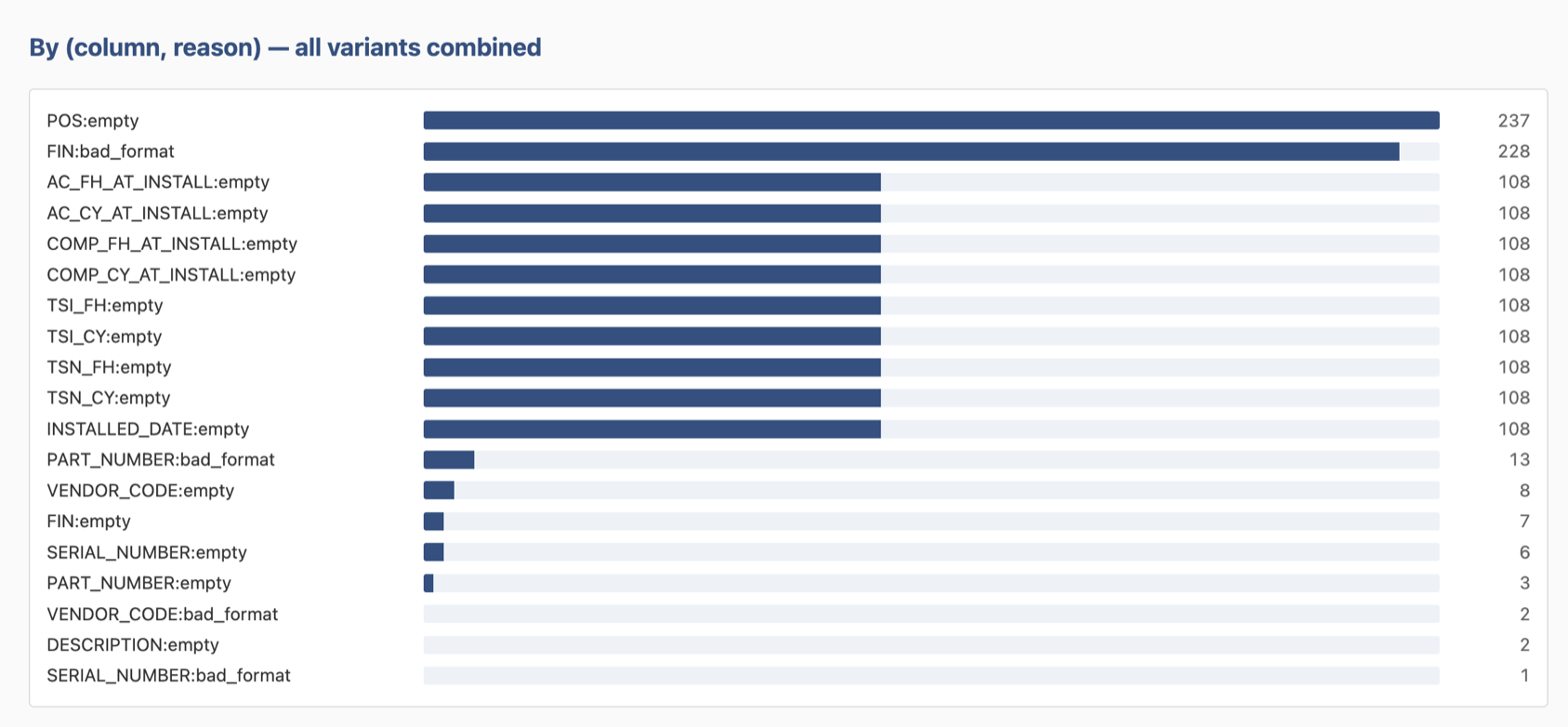
Cross-corpus issue analysis surfaces patterns at a glance. The two long bars at the top are not bugs — they are exactly the cells an analyst should eyeball first, surfaced from a corpus of 3,300 rows in milliseconds. Tuning a rule moves the bars; the chart is the feedback loop.
Four-level extraction pipeline
Different documents need different muscles. Cypher escalates per page:
- L1 — text-layer parsing for selectable PDFs (most operators, sub-second per page)
- L2 — layout-aware reconstruction for awkwardly-typeset tables (reserved)
- L3 — Tesseract OCR for scanned PDFs
- L4 — PaddleOCR
PP-Structurefor fringe-quality scans (Colab notebook) for advanced users.
A single document can be a mix. A 24-page OCCM with 13 text-layer pages and 11 scanned pages is parsed in one pass — text rows extracted directly, scanned pages routed to OCR, every row tagged with its provenance.
Privacy by design, not by promise
Cypher is a Pyodide application — Python compiled to WebAssembly, executing in the same JavaScript sandbox as a Wikipedia page. The PDF you select is read into the browser's memory and parsed there. No HTTP requests carry document bytes. No third-party telemetry. No cookies. Disconnect from the internet after the page loads and Cypher still works for the rest of the session.
For privacy-conscious operators, lease return work, ITAR-adjacent records, or anyone who has ever felt uncomfortable uploading a maintenance file to a "free SaaS extraction tool" — this is what you've been waiting for.
Open source, MIT-licensed
The full source is on GitHub. The validation rules are readable. The parsers are auditable. The privacy claims are verifiable line by line. Trust by inspection, not by trust me bro.
Real numbers, real PDFs
Adding a new operator would be a one-file affair. Tuning a rule is a one-line affair. Re-running the whole corpus and rebuilding the dashboard takes ninety seconds.
What's coming next
- Part Number technical documents cross-check — validate every extracted part number against an authoritative technical document library for each aircraft type, in-browser, without ever shipping the master list itself. Mathematically one-way, zero-trust by construction.
- Aircraft-type sub-variants — operator + airframe specificity for the rare cases where one operator emits different formats per fleet.
Try it today
Cypher launches publicly at [your URL here]. If you'd like a private walkthrough, drop me a line.
— Daniel Burke, Church Bay Consulting
Cypher is an open-source project under the MIT license. The deployed site is hosted on GitHub Pages with no analytics, no cookies, and no server. Source: [link to GitHub repo]. Built with Pyodide, pdfplumber, pdfminer.six, and the goodwill of every aviation engineer who has ever lost a Saturday to manual data entry.